Hoop.dev vs Runlayer: Where MCP Gateways End and Infrastructure Security Begins
AI agents are no longer chatbots. They execute code, query databases, call APIs, and operate inside production infrastructure. The question is no longer "should we let agents access our systems?" but "how do we control what they do once they're in?"
Two products are emerging to answer different parts of that question: Runlayer and Hoop. They are frequently mentioned together, but they solve fundamentally different problems at different layers of the stack. This post breaks down exactly where ea
Free White Paper
End-to-End Encryption + Infrastructure as Code Security Scanning: The Complete Guide
Architecture patterns, implementation strategies, and security best practices. Delivered to your inbox.
Andrios Robert
AI agents are no longer chatbots. They execute code, query databases, call APIs, and operate inside production infrastructure. The question is no longer "should we let agents access our systems?" but "how do we control what they do once they're in?"
Two products are emerging to answer different parts of that question: Runlayer and Hoop. They are frequently mentioned together, but they solve fundamentally different problems at different layers of the stack. This post breaks down exactly where each one sits, what it controls, and how to think about them when building your AI infrastructure security strategy.
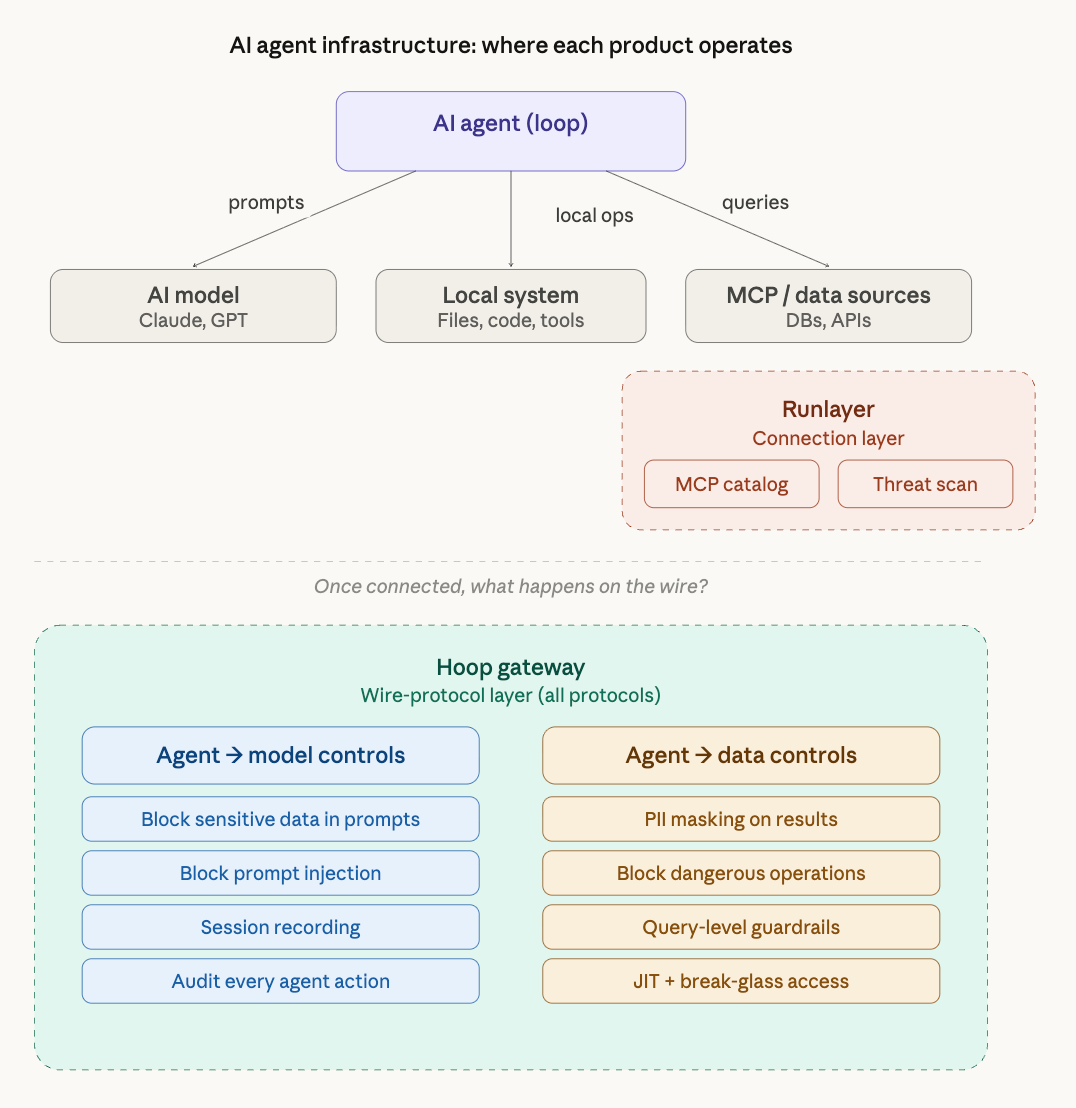
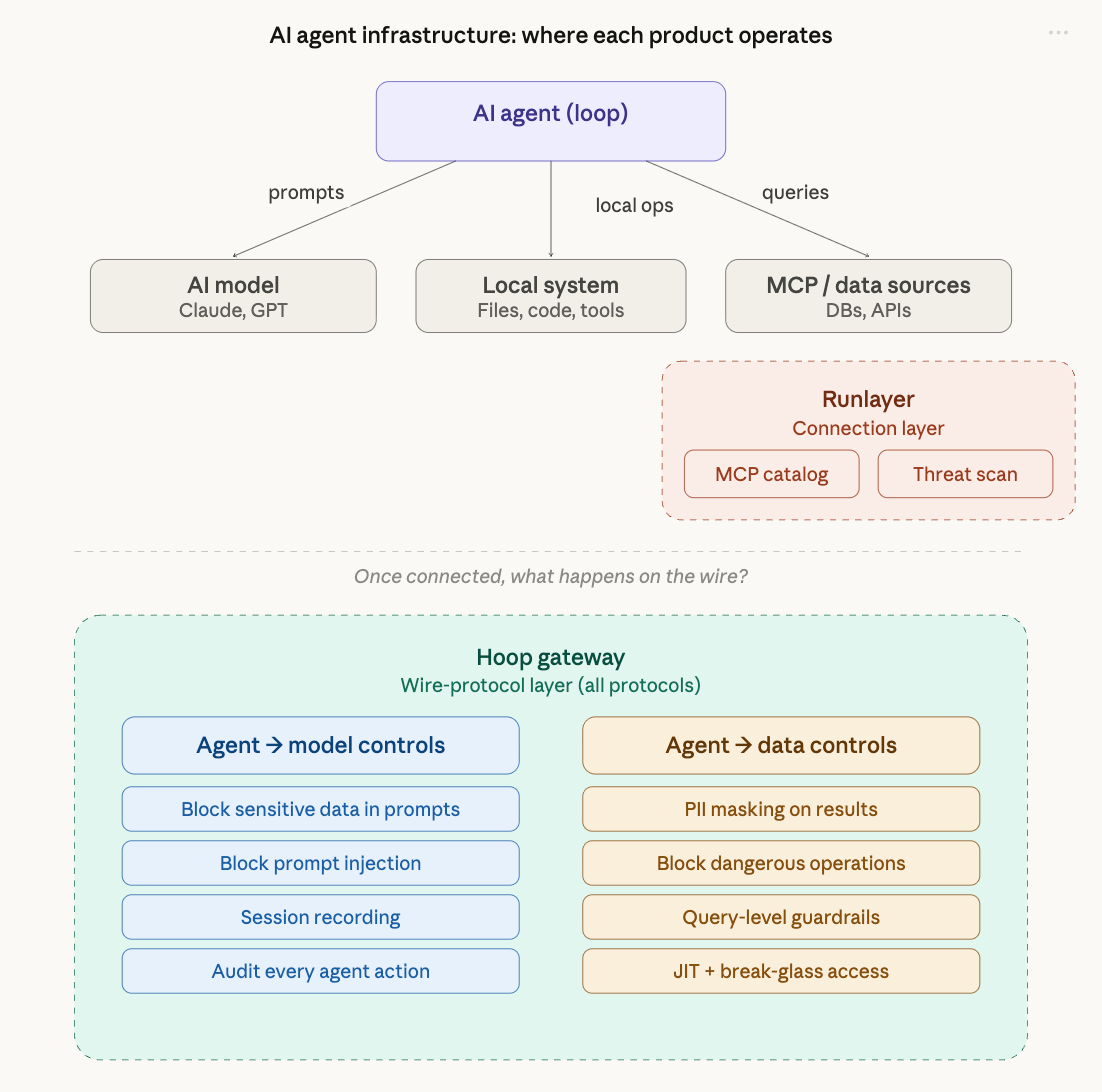
The architecture: how AI agents actually work
Before comparing products, it helps to understand the architecture that both products operate within.
An AI agent is a loop. It calls a model (Claude, GPT, etc.) repeatedly, interprets results, and takes actions. Those actions fall into two categories:
Local operations: writing files, generating code, creating presentations
Data operations: querying databases, calling APIs, reading from external systems
Local operations are useful but limited. The real power of agents comes from data operations, where an agent can query your Postgres database, call your internal APIs, and reason over live production data inside its loop.
MCP (Model Context Protocol) standardizes how agents connect to external data sources. Instead of building custom integrations for every database and API, MCP provides a single protocol that any agent client (Cursor, Claude Code, VS Code, ChatGPT) can use to reach any data source.
This creates a three-part architecture:
Agent → Model: the prompt/response path where the agent sends context and receives instructions
Agent → MCP/Data: the data path where the agent queries databases, APIs, and other systems
Agent → Local system: file writes, code execution, local tool use
The security surface area is enormous. Sensitive data flows in both directions. The model sees everything the agent sees. The agent can execute anything it has access to.
Where Runlayer sits
Runlayer is an MCP catalog and governance platform. It sits at the connection layer, controlling which MCP servers agents and developers can connect to.
Think of it as an app store for MCP servers, but enterprise-grade. IT approves which servers are in the catalog. Developers get one-click access to approved servers without editing JSON configs or managing API keys. Every connection is logged. Unapproved MCP servers are blocked.
Runlayer's core capabilities:
MCP server catalog: centralized registry of approved MCP servers with security scanning
Threat detection: scans for tool poisoning, prompt injection in MCP server definitions, and permission drift
Identity integration: SSO via Okta/Entra, SCIM, group-based permissions
Audit trails: logs every MCP connection and tool invocation
Shadow MCP detection: identifies when developers connect to unapproved MCP servers
One-click deployment: no JSON editing, works with 300+ MCP clients
Runlayer answers a critical question: which MCP servers can my developers use?
It does this well. The MCP ecosystem has thousands of servers, many of them unvetted, and some actively malicious. Having a curated, scanned catalog with identity-based access is a real problem that needs solving.
Continue reading? Get the full guide.
End-to-End Encryption + Infrastructure as Code Security Scanning: Architecture Patterns & Best Practices
Free. No spam. Unsubscribe anytime.
Where Hoop sits
Hoop is an infrastructure access gateway that operates at the wire protocol level. It sits between any actor (human, AI agent, or service account) and the actual infrastructure: databases, Kubernetes clusters, SSH servers, and MCP data sources.
Hoop doesn't care how you connected. It cares what you do once you're connected. Every query, every command, every response passes through the gateway, where it can be inspected, masked, blocked, or recorded.
Hoop's core capabilities:
Wire-protocol inspection: parses Postgres, MySQL, MongoDB, SSH, K8s, and MCP traffic in real time
Data masking: ML-powered PII detection that masks sensitive fields in query results before they reach the client (or the AI model)
Command guardrails: blocks destructive operations (DROP TABLE, DELETE without WHERE, rm -rf) before they execute
Session recording: full replay-grade capture of every session, command, and response
JIT access: time-bound, just-in-time access with automatic revocation
Break-glass workflows: approval flows via Slack/Teams/Jira for high-risk operations
Runbooks: parameterized, Git-stored templates for common operations with built-in guardrails
ML-powered, wire-level masking across all protocols
Command-level guardrails
No
Yes (block DROP, DELETE, rm -rf, etc.)
Session recording with replay
No
Yes, full session capture
JIT / time-bound access
No
Yes, with automatic revocation
Break-glass approval workflows
MCP server approval
Operational approval via Slack/Teams/Jira
SSH access governance
No
Yes
Kubernetes exec governance
No
Yes
Runbooks / parameterized templates
No
Yes, Git-based
SOC 2 / HIPAA / PCI evidence generation
Audit logs
Automated compliance evidence
Identity integration
Okta, Entra, SSO, SCIM
Okta, Entra, any IdP
AI agent governance
Controls which tools agents use
Controls what agents do with those tools
Open source
No
Yes (CNCF member)
Deployment model
SaaS or self-hosted VPC
SaaS or self-hosted (Docker, K8s, AWS)
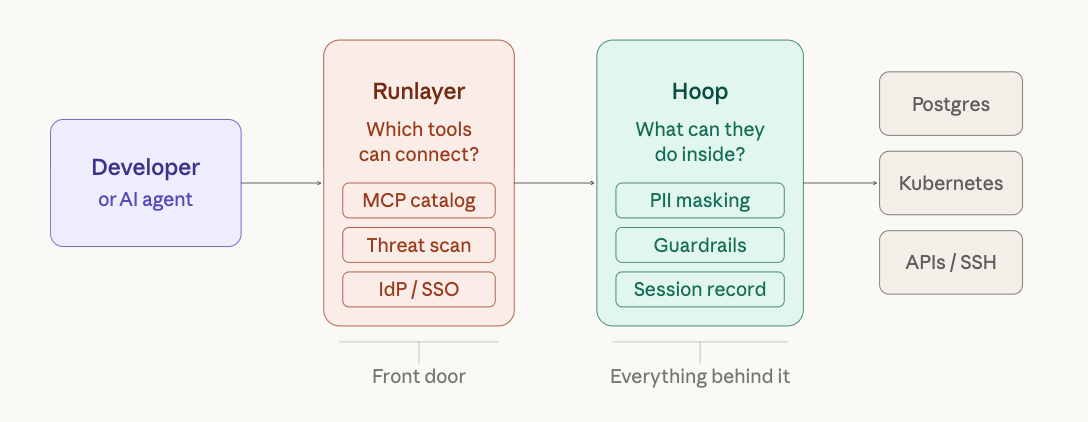
The "front door vs. everything behind it" framing
The simplest way to understand the difference:
Runlayer secures the front door. It controls which MCP servers agents and developers can connect to. It scans those servers for vulnerabilities. It enforces identity and permissions at the connection layer. This is valuable and necessary.
Hoop controls everything behind the door. Once an agent is connected to a database or API (whether through MCP or any other method), Hoop governs what it can do. It masks PII in responses. It blocks destructive commands. It records every interaction. It enforces JIT access and approval workflows.
These are not competing products. They operate at different layers. An enterprise that is serious about AI infrastructure security likely needs both: Runlayer to control the MCP catalog and prevent shadow tool sprawl, and Hoop to govern what happens at the data layer once agents are operating.
But if you have to prioritize, the question becomes: where is the actual risk?
The risk of an agent connecting to the wrong MCP server is real. But the risk of an agent running DELETE FROM users on your production database, or leaking PII through an unmasked query response that gets sent to an AI model, is existential.
Catalog governance prevents bad connections. Wire-level governance prevents bad outcomes.
When to use each
Use Runlayer when:
You need to govern which MCP servers developers can connect to from their IDEs
Shadow MCP usage is a growing concern
You want a curated, security-scanned catalog of approved tools
Your primary concern is MCP-specific attack vectors (tool poisoning, fake servers)
Use Hoop when:
You need to govern what humans and AI agents do inside production infrastructure
Engineers or agents access databases with sensitive data (PII, financial records, health data)
You need PII masking, command guardrails, and session recording at the data layer
You need JIT access, break-glass workflows, and compliance evidence generation
Your infrastructure spans databases, Kubernetes, SSH, and MCP
Use both when:
You want full-stack AI infrastructure security from tool discovery to data execution
Your compliance requirements demand both connection governance and session-level audit trails
You operate at enterprise scale with multiple teams, protocols, and data sources
Summary
The AI agent security landscape is splitting into two layers: connection governance (which tools can agents use?) and execution governance (what can agents do with those tools?). Runlayer is building the definitive platform for the first layer. Hoop is building the definitive platform for the second.
Both are necessary. Neither is sufficient alone. The companies that get AI agent security right will be the ones that think about both layers, not just the front door.
Get started
See hoop.dev in action
One gateway for every database, container, and AI agent. Deploy in minutes.